
Quando si applica una regressione lineare, la devianza totale (TSS, dall’inglese “total sum of square”), che rappresenta la somma degli scarti dalla media al quadrato, può essere divisa in due fattori distinti:
- il primo, chiamato anche devianza non spiegata, rappresenta la varianza dei valori residui del modello, ovvero la devianza di ciò che il modello non riesce a spiegare (ESS, dall’inglese “error sum of square”);
- il secondo, chiamato anche devianza spiegata rappresenta la devianza del modello stesso (RSS, dall’inglese “regression sum of square”).
Questa scomposizione è molto utile per capire quanto effettivamente il modello riesca a spiegare della composizione dei dati. Permette infatti di costruire un indice molto importante, l’
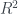
Si può dimostrare che vale questa scomposizione con dei semplici passaggi algebrici. Ricordando che la media dei valori osservati coincide con la media dei valori teorici, possiamo scrivere:


Il terzo termine della scomposizione si annulla, infatti:


Che coincide esattamente con le derivate parziali poste uguali a 0 nel calcolo dei coefficienti della retta di regressione.
Una particolarità dell’indice
![R^2 = \frac{RSS}{TSS} = \frac{\sum_{i = 1}^{n} (y_i - \hat{y}_i)^2}{n\sigma ^2_y} = \frac{\sum_{i = 1}^{n} [\beta(x_i - \hat{x}_i)]^2}{n\sigma ^2_y} =](https://s0.wp.com/latex.php?latex=R%5E2+%3D+%5Cfrac%7BRSS%7D%7BTSS%7D+%3D+%5Cfrac%7B%5Csum_%7Bi+%3D+1%7D%5E%7Bn%7D+%28y_i+-+%5Chat%7By%7D_i%29%5E2%7D%7Bn%5Csigma+%5E2_y%7D+%3D++%5Cfrac%7B%5Csum_%7Bi+%3D+1%7D%5E%7Bn%7D+%5B%5Cbeta%28x_i+-+%5Chat%7Bx%7D_i%29%5D%5E2%7D%7Bn%5Csigma+%5E2_y%7D+%3D+&bg=ffffff&fg=333A42&s=0&c=20201002)

Tutto questo ragionamento può naturalmente essere applicato anche alla varianza, dividendo la devianza per n.
