
Il teorema del limite centrale funzionale, detto anche teorema di Donsker, è un’estensione funzionale del classico teorema del limite centrale (TLC). Il teorema del limite centrale è uno dei teoremi più importanti della teoria delle probabilità. In verità esso costituisce una classe di teoremi, di cui una delle formulazioni più note è la seguente:
Sia 

![E[X_j] = \mu](https://s0.wp.com/latex.php?latex=E%5BX_j%5D+%3D+%5Cmu&bg=ffffff&fg=333A42&s=0&c=20201002)
![Var[X_j] = \sigma^2 \ \forall j,](https://s0.wp.com/latex.php?latex=Var%5BX_j%5D+%3D+%5Csigma%5E2++%5C++%5Cforall+j%2C&bg=ffffff&fg=333A42&s=0&c=20201002)

Posto


In altre parole, dato un numero sufficiente (solitamente almeno 25 o 30) di osservazioni indipendenti generate da una stessa variabile aleatoria, se si considera la standardizzazione della somma di queste variabili, ovvero si toglie, dalla somma, n volte la media teorica e si divide per la deviazione standard teorica diviso la radice della numerosità campionaria, questa si distribuirà come una normale standard.
Il teorema di Donsker, in maniera simile, estende i risultati del limite centrale. Consideriamo infatti una successione di variabili aleatorie indipendenti e identicamente distribuite



![W^{(n)}(t) = \frac{S_{\lfloor n t \rfloor}}{\sqrt{n}}, \hspace{3ex} t \in [0,1]](https://s0.wp.com/latex.php?latex=W%5E%7B%28n%29%7D%28t%29+%3D+%5Cfrac%7BS_%7B%5Clfloor+n+t+%5Crfloor%7D%7D%7B%5Csqrt%7Bn%7D%7D%2C+%5Chspace%7B3ex%7D+t+%5Cin+%5B0%2C1%5D&bg=ffffff&fg=333A42&s=0&c=20201002)
Il TLC afferma che




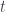













![[x_0, x_1 ]](https://s0.wp.com/latex.php?latex=%5Bx_0%2C+x_1+%5D&bg=ffffff&fg=333A42&s=0&c=20201002)

![(x_1, x_2 ]](https://s0.wp.com/latex.php?latex=%28x_1%2C+x_2+%5D&bg=ffffff&fg=333A42&s=0&c=20201002)

![(x_n-1, x_n ]](https://s0.wp.com/latex.php?latex=%28x_n-1%2C+x_n+%5D&bg=ffffff&fg=333A42&s=0&c=20201002)



























