In teoria dei numeri, l’identità di Legendre-de Polignac (o formula di Legendre), è una formula che fornisce l’esponente massimo di un numero primo p che divide il fattoriale n!. In altri termini, questa formula permette di ricavare una scomposizione, fissato un numero primo p, di un fattoriale nel seguente modo:
dove R è un intero residuo e è il massimo esponente di p che permette tale divisione. Questa è chiamata anche valutazione p-adica di n ed è possibile attuarla per qualsiasi numero primop. Nonostante possa sembrare una richiesta decisamente articolata, la soluzione è di per sé molto semplice. Per comodità, indicheremo con la valutazione p-adica di n!, ovvero la funzione che restituisce l’esponente massimo della divisione di n! per un numero primo p. Il suo calcolo è molto semplice, la formula generale infatti è la seguente:
dove sarebbe la parte intera della divisione di n per .
Questa formula può essere ulteriormente semplificata se si considera la rappresentazione binaria dei numeri (ovvero esattamente come sono rappresentati su un computer). Infatti, in questo caso la formula sarà la seguente:
per cui il calcolo in un programma viene notevolmente semplificato.
Gli algoritmi di manipolazione dei bits permettono, in maniera elegante ed efficacie, di risolvere problemi come il trovare l’ultima cifra significativa di un numero rappresentato in binario (LSB, dall’inglese Least Significant Bit), oppure il contare il numero di setbit (ovvero bit pari a 1) in un numero qualsiasi codificato in binario. Queste domande sono spesso poste durante colloqui di lavoro presso grandi società, come Google e Amazon.
Determinare il LSB di N
Valutiamo ora il problema del trovare l’ultima cifra significativa di un numero N rappresentato in binario. Per farlo, si utilizza l’operatore logico And in VB.NET, equivalente in C# all’operatore &, eseguendo l’operazione N And 1. In questo modo il programma valuterà solo l’ultimo bit del numero N e restituirà 1 se è pari a 1, 0 altrimenti. In questo modo, è possibile agilmente creare un programma per controllare se un numero risulta essere dispari o meno (poichè, se dispari, terminerà con un 1 nella sua codifica in binario).
C#
public bool isOdd(int n)
{
if ((n & 1) == 1)
return true;
else
return false;
}
VB.NET
Public Function IsOdd(ByVal N As Integer) As Boolean
If (N And 1) = 1 Then
Return True
Else
Return False
End If
End Function
Contare il numero di setbit in N
Algoritmo Naive
Un altro domanda classicamente posta durante i colloqui di lavoro, consiste nel determinare il numero di bit pari ad 1 nella codifica binaria di un dato numero N. Anche questo quesito può essere svolto elegantemente. Si può costruire un algoritmo Naive andando a complicare leggermente la soluzione del quesito precedente. Abbiamo infatti visto come è possibile valutare l’ultimo bit di un numero N codificato in binario. A questo punto, tramite l’operatore di scorrimento shift, identificato in C# e in VB.NET con il simbolo “>>“, è possibile traslare di una posizione verso destra i bit che compongono la sequenza della rappresentazione binaria di N. Si procederà quindi a valutare iterativamente l’ultimo bit significativo, fino a che il numero di partenza non sarà pari a 0. Graficamente, può essere rappresentato come segue. Prendiamo in considerazione il numero 25 e la sua rappresentazione binaria:
Step 1: N
1
1
0
0
1
N&1 = 1
Step 2: N>>1
–
1
1
0
0
N&1 = 0
Step 3: N>>1
–
–
1
1
0
N&1 = 0
Step 4: N>>1
–
–
–
1
1
N&1 = 1
Step 5: N>>1
–
–
–
–
1
N&1 = 1
Fine
–
–
–
–
–
Tot = 3
Una semplice implementazione di questo algoritmo in C# e VB.NET è la seguente:
C#
public int countSetBitNaive(int n)
{
int sumSetBit = 0;
while (n != 0)
{
sumSetBit += n & 1;
n >>= 1;
}
return sumSetBit;
}
VB.NET
Function CountSetBitNaive(N As Integer) As Integer
Dim SumSetBit As Integer = 0
Do While N <> 0
SumSetBit += N And 1
N >>= 1
Loop
Return SumSetBit
End Function
Algoritmo di Kernighan
Un altro modo per implementare questo algoritmo, velocizzando il procedimento ad un numero di passaggi pari all’effettivo numero di bit pari ad 1, è attraverso l’algoritmo di Kernighan. Questo algoritmo sfrutta la relazione che esiste tra un numero e il precedente, ovvero tra N e (N-1), quando sono codificati in binario. Se infatti si applica l’operazione And su questi due numeri, si ottiene l’azzeramento del primo bit di N a partire da destra che risulta essere pari a 1. In questo modo è possibile fare un loop in cui viene contato semplicemente il numero di volte in cui l’operazione viene eseguita prima che il numero diventi pari a 0. Un’implementazione di questo algoritmo è la seguente:
C#
public int countSetBitKernighan(int n)
{
int sumSetBit = 0;
while (n != 0)
{
n = n & n-1;
sumSetBit += 1;
}
return sumSetBit;
}
VB.NET
Function CountSetBitKernighan(N As Integer) As Integer
Dim SumSetBit As Integer = 0
Do While N <> 0
N = N AND N - 1
SumSetBit += 1
Loop
Return SumSetBit
End Function
Testare se N è una potenza di 2
Un altro quesito facilmente risolvibile attraverso gli operatori logici quando, N è codificato in binario, è il controllare se N risulta essere una potenza di 2 o meno. Questo può essere rapidamente risolto ricordando che se N è una potenza di 2, la sua codifica in binario sarà uguale ad un primo bit pari a 1 seguito da tanti bit pari a 0 quanto è la potenza di 2. Ad esempio, 16, che è pari a 2^4, sarà rappresentato in binario dal numero 1 0 0 0 0. Per verificare allora se un numero è una potenza di 2 basterà allora verificare che N And (N-1) restituisce subito come risultato 0. Un’implementazione di questo algoritmo in C# e VB.NET è la seguente:
C#
public bool isPowerOf2(int n)
{
if ((n & n - 1) == 0)
return true;
else
return false;
}
VB.NET
Public Function IsPowerOf2(ByVal N As Integer) As Boolean
If (N And N - 1) = 0 Then
Return True
Else
Return False
End If
End Function
Determinare la massima potenza di 2 che divide N
Un ultimo quesito risolto in questo articolo riguarda il trovare la massima potenza di 2 che divide un numero N. Considerando la sua scrittura in binario, è facile notare che essa è esattamente pari al primo bit (partendo da destra) pari ad 1. Basterà, quindi, porre pari a 0 tutti i bit che seguono il primo bit pari ad 1. Per farlo non servirà altro che eseguire l’operazione N And Not (N – 1). Una semplice implementazione di questo algoritmo è la seguente:
C#
public int maxPowerOf2_factor(int n)
{
return (n & !(n - 1));
}
VB.NET
Public Function MaxPowerOf2_factor(ByVal N As Integer) As Integer
Return (N And Not (N - 1))
End Function
In informatica e programmazione, un operatore è un simbolo che specifica quale legge applicare a uno o più operandi, per generare un risultato. Gli operatori possono essere classificati in base al numero di operandi che accettano, ovvero in base al numero di dati su cui lavorano, o in base alle operazioni che svolgono e ad i risultati che forniscono. La prima divisione degli operatori presenti in C# e VB.NET in base al numero di operandi che accettano è la seguente:
operatori unari (o unary) sono operatori che richiedono un solo operando e sono ad esempio l’operatore not in VB.NET e !in C#;
operatori binari (o binary) lavorano su due operandi, come ad esempio gli operatori aritmetici più comuni o quelli di assegnamento;
operatori ternari (o ternary) lavorano su tre operandi; sono operatori non molto comuni, uno dei rari esempi è l’operatore condizionale, usato in programmazione, rappresentato in C# attraverso il simbolo “?” e in VB.NET attraverso la funzione If(). Il suo funzionamento è relativamente semplice. In C# la sintassi A?B:C significa che se A risulta essere vero allora il programma restituisce B, altrimenti viene restituito C. Analogamente, questa operazione può essere compiute in VB.NET attraverso la sintassi If(A,B,C).
Una suddivisione per funzionalità degli operatori è la seguente:
aritmetici: sono +, -, *, /, %, \ e lavorano su due operandi;
incremento e decremento: sono unari, rispettivamente aumentano o diminuiscono di uno l’unico operando che prendono;
logici booleni: lavorano su dati booleani, ovvero variabili che possono assumere solo i valori vero e falso e servono a formulare condizioni composte; ne sono un esempio in NOT, AND, OR, XORVB.NET, o gli equivalenti in C#!, &, |, ^;
bitwise: consentono di manipolare direttamente i bit di un valore e sono uguali agli operatori logici, fatta eccezione per !, che viene tradotto con ~;
relazione: sono operatori binary che consentono di controllare la relazione tra due operandi, sono <>, =, <, >, <= , >=, is, isnot in VB.NET e C#, fatta eccezione per i primi due dove in C# sono tradotti con !=, ==;
concatenazione di stringhe: rispettivamente & e + in VB.NET e C#, servono per la concatenazione di stringhe;
condizionali In VB.NET si utilizzano ANDALSO, ORELSE, in C# sono tradotti con &&, ||. Questi operatori differiscono dai logici perché quest’ultimi valutano i due termini operandi in ogni caso, mentre gli operatori condizionali valutano il secondo operando solo se strettamente necessario. Questo procedimento è detto short circuiting.
Quando si applica una regressione lineare, la devianza totale (TSS, dall’inglese “total sum of square”), che rappresenta la somma degli scarti dalla media al quadrato, può essere divisa in due fattori distinti:
il primo, chiamato anche devianza non spiegata, rappresenta la varianza dei valori residui del modello, ovvero la devianza di ciò che il modello non riesce a spiegare (ESS, dall’inglese “error sum of square”);
il secondo, chiamato anche devianza spiegata rappresenta la devianza del modello stesso (RSS, dall’inglese “regression sum of square”).
Questa scomposizione è molto utile per capire quanto effettivamente il modello riesca a spiegare della composizione dei dati. Permette infatti di costruire un indice molto importante, l’ di Pearson, definito come il rapporto tra la devianza spiegata e la devianza totale. Questo indice varia tra 0 e 1. Se assume valore pari a 0, significa che il modello non riesce a spiegare nulla della variabilità dei dati; se invece assume valore pari a 1 significa che il modello prevede perfettamente tutti i dati osservati (i valori realmente osservati saranno quindi distribuiti esattamente sulla retta di regressione).
Si può dimostrare che vale questa scomposizione con dei semplici passaggi algebrici. Ricordando che la media dei valori osservati coincide con la media dei valori teorici, possiamo scrivere:
Il terzo termine della scomposizione si annulla, infatti:
Che coincide esattamente con le derivate parziali poste uguali a 0 nel calcolo dei coefficienti della retta di regressione.
Una particolarità dell’indice è che nella regressione lineare, coincide esattamente con il quadrato dell’indice di correlazione. Questo è facilmente dimostrabile attraverso i seguenti passaggi:
Tutto questo ragionamento può naturalmente essere applicato anche alla varianza, dividendo la devianza per n.
Quando si studiano due variabili è spesso interessante studiare se esiste una certa relazione che le leghi. Questo può portare a molteplici vantaggi, come ad esempio poter predire i valori di una conoscendo solo l’altra, o anche riuscire a controllare i valori di una variabile direttamente non controllabile attraverso variabili più facilmente controllabili.
La relazione più semplice è sicuramente quella lineare. Questa può essere quantificata dal coefficiente di correlazione, che può assumere valori che variano da -1 a 1 a seconda dell’intensità e del rapporto di dipendenza tra le due variabili. Va notato comunque che il coefficiente di relazione pari a 0 non implica che non esista una dipendenza tra le due variabili, ma solo che non esiste una dipendenza lineare.
Questa dipendenza lineare può essere studiata e modellata più approfonditamente attraverso una regressione lineare. Dato un campione composto da due variabili X e Y, supponendo di voler studiare il valore della Y dipendentemente dal valore della X, la regressione lineare consiste nell’individuare la retta funzione di X che minimizza le distanze tra i valori teorici delle Y con i valori reali. Ovvero, si cerca quella retta che ad ogni X associa un valore teorica della Y attraverso la formula:
e tale che la somma delle distanze da tra questi valori e le Y realmente osservate sia minimo. In formule:
Si cercano quindi i valori di e che minimizzino questa distanza. Per fare ciò, si considerano le derivate parziali e si eguagliano a 0 come segue:
Per semplicità, denotiamo e . Con dei semplici passaggi algebrici otteniamo:
Questi valori di e di sono proprio i valori che creano la retta di regressione o retta dei minimi quadrati, dato che la distanza utilizzata per il suo calcolo è, appunto, la canonica distanza euclidea. Si può facilmente dimostrare che questa retta passa sempre per il baricentro dei dati, ovvero per il punto determinato dal valor medio della X e da quello della Y. Inoltre la media dei valori teorici, ottenuti attraverso questa retta, coincide esattamente con la media dei valori osservati. Visto da un’altra prospettiva, questa informazione implica che la somma degli scarti dalla retta di regressione è pari a 0.
I tipi numerici a “precisione arbitraria” (conosciuti anche come interi a “precisione infinita” o bignum), permettono la rappresentazione del numero attraverso uno spazio mutevole di memoria, aumentando enormemente il range di rappresentazione del numero. L’unico limite si pone, infatti, per la finitezza della memoria del computer. Tuttavia, con 8 KB di memoria, si può arrivare a rappresentare numeri di 2466 cifre.
Alcuni linguaggi supportano direttamente i numeri a precisione arbitraria. In altri linguaggi è invece necessario importare delle apposite librerie. La libreria System.Numerics contiene una classe BigInteger i cui oggetti possono rappresentare numeri interi di lunghezza arbitraria. Questi oggetti non utilizzare i classici operatori aritmetici ( + * – / =), ma è necessario utilizzare i metodi forniti dalla classe stessa, che sono: add, multiply, subtract, equals. Per poter inizializzare i numeri BigInteger, è necessario utilizzare un metodo Parse per poter assegnare l’intero arbitrario come stringa. Questo è necessario poiché altrimenti non sarebbe possibile rappresentare numeri di queste dimensioni.
Il fattoriale di un numero n, indicato con la simbologia n!, rappresenta il prodotto di tutti gli interi da 1 fino al numero n compresi, ovvero:
Il calcolo del fattoriale seguendo la formula canonica può rivelarsi essere molto lungo e molto esigente, dal punto di vista del costo computazionale. Tuttavia esistono diversi algoritmi che permettono il calcolo del fattoriale in un minor lasso di tempo. I principali sono:
SpliRecursive: è l’algoritmo più rapido che non utilizza la fattorizzazione in primi ed è relativamente semplice da implementare;
PrimeSwing: è l’algoritmo conosciuto asintoticamente più veloce per calcolare n!; si basa sul concetto di “Swing Numbers”, calcolando il fattoriale tramite la scomposizione in fattori primi;
Poor Man’s: questo algoritmo non utilizza nessuna libreria Big-Integer, può essere facilmente implementato su qualsiasi computer ed è rapido fino a 10000 fattoriale.
ParallelPrimeSwing: corrisponde all’algoritmo PrimeSwing con prestazioni migliorate grazie a metodi di programmazione concorrenti e sfruttando così processori multipli.
In programmazione la gestione degli errori è il processo di risposta all’occorrenza di exceptions, che sono condizioni anomale o speciali che richiedono una gestione speciale. Queste eccezioni (o errori) vengono “lanciate” automaticamente dal compilatore quando si imbatte in problemi che interrompono la normale esecuzione del programma (come, ad esempio, overflow). In poche parole, quando si verifica un imprevisto, il metodo attivo “lancia” (throw) un’eccezione che viene passata al metodo chiamante. Il metodo attivo termina quindi l’esecuzione. Per default, un metodo che riceve un’eccezione termina l’esecuzione e passa l’eccezione al metodo chiamante. Quando l’eccezione raggiunge il metodo main (ovvero il metodo principale), l’esecuzione del programma termina stampando un opportuno messaggio di errore.
Tuttavia, è possibile gestire gli errori in maniera tale da non interrompere il programma e gestendo anche la stampa del messaggio di errore, lasciando al programmatore la possibilità di gestirlo nella maniera più consona. La struttura Try, Catch serve esattamente a questo. Si compone da due blocchi di comandi, più un terzo non obbligatorio, che hanno le seguenti funzioni:
il blocco Try contiene le istruzioni da eseguire, che potrebbero generare eccezioni e che si vuole controllare;
il blocco Catch contiene la gestione degli errori che potrebbero essere generati durante l’esecuzione del Try (è possibile aggiungere più blocchi Catch per gestire separatamente le diverse tipologie di eccezioni che il Try può generare);
il blocco Finally può, facoltativamente, essere messo alla fine e comprende il blocco di istruzioni da eseguire indipendentemente dall’esito delle istruzioni contenute nel blocco Try.
La sintassi del Try, Catch per quanto riguarda C# e VB.NET è la seguente:
Il blocco Try, Catch funziona abbastanza linearmente; vengono eseguite le istruzioni contenute nel Try. Se l’esecuzione procede senza aver generato nessun errore, vengono eseguite le istruzioni presenti nel Finally (se presente) e il programma prosegue con la prima istruzione dopo il blocco Try, Catch. Se invece vengono generate delle eccezioni durante il Try, l’esecuzione termina alla prima istruzione che genera errore(le istruzioni successive a quella incriminata non vengono quindi eseguite) e viene eseguita la gestione presente nel blocco Catch relativo al tipo di errore generato (può anche darsi che il Catch gestisca qualsiasi generico errore, non è necessario specificare un Catch per ogni errore che potrebbe essere generato). Infine vengono comunque eseguite le istruzioni nel Finally.
Si può gestire un’eccezione anche in maniera più “pigra”, inserendo nella definizione del metodo una “throw exception“. Questo comando in sostanza significa che il metodo appena eseguito potrebbe generare una eccezione e che il metodo chiamante deve occuparsi della sua gestione.
In C# e VB.NET il comportamento delle eccezioni non gestite è leggermente differente:
in C# l’ultimo metodo chiamante che non comprende il comando “throw exception” deve gestire l’eccezione con un blocco Try, Catch;
in VB.NET: è presente un gestore di eventi (“Eccezione non gestita”) che consente, , di intercettare l’eccezione in cima alla pila e di definire la sua gestione.
In matematica, il coefficiente binomiale è un numero intero non negativo definito dalla seguente formula:
Questo numero è dimostrato corrispondere alle combinazioni semplici di n elementi di classe k, che equivale a dire il numero di sottoinsiemi di k elementi estratti da un insieme di n elementi (non considerando rilevante l’ordine degli insiemi).
Le combinazioni sono parte del calcolo combinatorio, una branda della matematica che studia i modi per raggruppare e/o ordinare secondo date regole gli elementi di un insieme finito di oggetti. Esistono 3 principali categorie di raggrupamento, ognuna delle quali può essere considerata con o senza ripetizioni (ovvero permettendo o meno l’estrazione di uno stesso elemento di un insieme più di una volta). Si possono distinguere infatti:
Permutazioni:
semplici (senza ripetizioni)
con ripetizioni
Disposizioni:
semplici (senza ripetizioni)
con ripetizioni
Combinazioni:
semplici (senza ripetizioni)
con ripetizioni
Una permutazione di un insieme di oggetti è una presentazione ordinata, cioè una sequenza, dei suoi elementi nella quale ogni oggetto viene presentato una ed una sola volta. Nel caso in cui gli n elementi dell’insieme siano tutti diversi, si parla di permutazioni semplici e si calcolano con la formula:
Se invece l’insieme contiene delle ripetizioni, occorre utilizzare la formula per le permutazioni con ripetizione, poiché alcuni insiemi risulteranno uguali tra loro. Indicando con il numero di volte che si ripetono r elementi dell’insieme, la formula delle permutazioni sarà la seguente:
Una disposizione semplice di k elementi da un insieme di n è una collezione ordinata nella quale non si può avere la ripetizione di uno stesso oggetto e si calcola con la seguente formula:
Nel caso in cui invece fosse possibile avere le ripetizioni di uno stesso oggetto, allora bisognerà utilizzare la formula delle disposizioni con ripetizione:
Infine, le combinazioni semplici, come già detto, rappresentano il numero di sottoinsiemi non ordinati di k elementi estratti da un insieme di n elementi. La formula può essere ricavata attraverso le permutazioni e le disposizioni e, come si vedrà, coincide esattamente con il coefficiente binomiale. Infatti le combinazioni semplici possono essere viste come il numero di insiemi ordinati di k elementi che si possono ottenere da un insieme di n diviso il numero di permutazione di ogni sottoinsieme, ovvero attraverso il rapporto tra e :
Una delle proprietà principali del coefficiente binomiale è che permette di ricavare i coefficienti che precedono i termini ottenuti dallo sviluppo di un binomio di potenza p, permettendo di sviluppare il “Triangolo di Tartaglia”, ovvero una sorta di piramide dei coefficienti associati ad ogni esponente.
p = 0 1 p = 1 1 1 p = 2 1 2 1 p = 3 1 3 3 1 p = 4 1 4 6 4 1 p = 5 1 5 10 10 5 1 p = 6 1 6 15 20 15 6 1 p = 7 1 7 21 35 35 21 7 1
Il coefficiente binomiale presenta inoltre diverse proprietà molto utili. La prima riguarda la simmetria del coefficiente binomiale. Infatti:
Questa proprietà è vera poichè:
Inoltre, dato che 0! = 1 per definizione, è vera anche le seguente proprietà:
Questa proprietà è vera poichè:
Esistono anche delle proprietà che permettono il calcolo ricorsivo del coefficiente binomiale. Infatti, è possibile scomporre il coefficiente binomiale nel seguente modo:
In questo modo è possibile ottenere due strutture di ricorrenza per il coefficiente binomiale, ovvero:
La covarianza tra due variabili statistiche X e Y, indicata con è un indice di variabilità congiunta che fornisce una misura di quanto le due varino assieme, ovvero della loro dipendenza. Può essere calcolata solo su due insiemi con la stessa numerosità. è possibile costruire un indice relativo della covarianza, denominato indice di correlazione di Bravais-Pearson, in maniera tale che vari tra -1 e 1 (al fine di ottenere una miglior comprensione della dipendenza, essendo la covarianza legata all’ordine di grandezza delle osservazioni), dividendo il suo valore per il prodotto delle deviazioni standard delle due varibili. La formula dell’indice di correlazione è la seguente:
Indicando con la media della variabile X e con la media della variabile Y, date n osservazioni per entrambe le variabili, la formula per calcolare la covarianza è la seguente:
Questa formula, come anche la media e la varianza, presenta diversi limiti in un contesto informatico. Infatti, è necessario la conoscenza preliminare del numero di osservazioni, cosa che non sempre è realizzabile. Per ovviare a questo problema si utilizza una relazione di ricorrenza, ovvero una formula ricorsiva che esprime il valore del termine n-esimo di una successione in funzione dei termini precedenti (in particolare, in questo caso, solo del termine precedente). In questo modo non è più necessaria la conoscenza preliminare del numero di dati che verranno forniti in input, ma è possibile aggiornare ricorsivamente il valore della covarianza ad ogni nuova coppia di osservazioni.
Possiamo riscrivere la somma dei prodotti delle osservazioni di due variabili X e Y, a cui sono state sottratte due costanti arbitrarie e , nel seguente modo:
Dove indica la somma dei prodotti ad un dato passo n. Ponendo e pari alle medie delle variabili al passo n-1, ovvero e , possiamo riscrivere la formula come segue:
è quindi possibile aggiornare la somma dei prodotti in due diversi modi equivalenti:










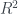




![R^2 = \frac{RSS}{TSS} = \frac{\sum_{i = 1}^{n} (y_i - \hat{y}_i)^2}{n\sigma ^2_y} = \frac{\sum_{i = 1}^{n} [\beta(x_i - \hat{x}_i)]^2}{n\sigma ^2_y} =](https://s0.wp.com/latex.php?latex=R%5E2+%3D+%5Cfrac%7BRSS%7D%7BTSS%7D+%3D+%5Cfrac%7B%5Csum_%7Bi+%3D+1%7D%5E%7Bn%7D+%28y_i+-+%5Chat%7By%7D_i%29%5E2%7D%7Bn%5Csigma+%5E2_y%7D+%3D++%5Cfrac%7B%5Csum_%7Bi+%3D+1%7D%5E%7Bn%7D+%5B%5Cbeta%28x_i+-+%5Chat%7Bx%7D_i%29%5D%5E2%7D%7Bn%5Csigma+%5E2_y%7D+%3D+&bg=ffffff&fg=333A42&s=0&c=20201002)
































![{n \choose k} = {{n!}\over{k!(n-k)!}} = {{n!}\over{(n-k)![n-(n-k)]!}} = {n \choose n-k}](https://s0.wp.com/latex.php?latex=%7Bn+%5Cchoose+k%7D+%3D+%7B%7Bn%21%7D%5Cover%7Bk%21%28n-k%29%21%7D%7D+%3D+%7B%7Bn%21%7D%5Cover%7B%28n-k%29%21%5Bn-%28n-k%29%5D%21%7D%7D+%3D+%7Bn+%5Cchoose+n-k%7D+&bg=ffffff&fg=333A42&s=0&c=20201002)













![\sum_{i=1}^n(x_i-c_1)(y_i-c_2)= \sum_{i=1}^n [(x_i-\bar{x}_n)(y_i-\bar{y}_n) ] \cdot [(\bar{x}_n - c_1)(\bar{y}_n - c_2)] =](https://s0.wp.com/latex.php?latex=%5Csum_%7Bi%3D1%7D%5En%28x_i-c_1%29%28y_i-c_2%29%3D+%5Csum_%7Bi%3D1%7D%5En+%5B%28x_i-%5Cbar%7Bx%7D_n%29%28y_i-%5Cbar%7By%7D_n%29+%5D+%5Ccdot+%5B%28%5Cbar%7Bx%7D_n+-+c_1%29%28%5Cbar%7By%7D_n+-+c_2%29%5D+%3D+&bg=ffffff&fg=333A42&s=0&c=20201002)










