Non mi fido molto delle statistiche, perché un uomo con la testa nel forno acceso e i piedi nel congelatore statisticamente ha una temperatura media.
Charles Bukowski
Questo blog raccoglie piccole ricerche di ambito statistico-finanziario e del codice informatico che le supporta. È realizzato nell’ambito del corso di laurea magistrale in Scienze Statistiche.
Gli articoli pubblicati sono sviluppati sulle ricerche proposte dal professor T.Gastaldi durante le lezioni del corso di “Statistica Applicata”. Sono divisi un due categorie principali:
Finanzia e Statistica;
Programmazione.
Nella prima categoria rientrano, appunto, ricerche di vario ambito legate sia all’ambiente lavorativo e alle possibilità lavorative per i laureati in lauree statistiche, mentre la seconda raccoglie ricerche più specifiche sulle competenze informatiche richieste allo statistico.
Una strategia di trading è un piano prefissato e costruito per ottenere un guadagno secondo le esigenze di chi la sta costruendo. Si tratta, quindi, della strategia di base per definire le regole di vendita o di acquisto degli strumenti finanziari, in modo da favorire un guadagno che può essere stato pianificato come a lungo o breve termine. Una strategia di trading adeguatamente studiata deve avere diverse proprietà, che la rendono ottimale: verificabilità, quantificabilità, coerenza e obiettività.
Esistono, naturalmente, un’infinità di diverse tipologie di strategie di marketing. Tuttavia, si possono definire quattro stili e strategie principali. Uno stile di trading è un insieme di preferenze che determinano la regole di gestione delle trade. Si basa su diversi fattori, quali, ad esempio, dimensioni del’account, tempo che si può dedicare al trading e tolleranza al rischio. Questi quattro stili sono:
Trading di posizione: comporta una negoziazione per un lungo periodo di tempo. Si valutano principalmente gli andamenti generali dei mercati, in quanto le fluttuazioni a breve termine non sono rilevanti, poichè vengono “diluite” dal lungo periodo di tempo in cui si operano queste transazioni. Il trading di posizione implica l’apertura di un numero inferiore di negoziazioni rispetto ad altri stili di trading, ma le posizioni tenderanno ad avere un valore più elevato.
Swing trading: è uno stile che si concentra sul prendere una posizione all’interno di una mossa più ampia. Implica una negoziazione per diversi giorni o settimane, al fine di trarre vantaggio dai movimenti del mercato a breve e medio termine. L’obiettivo generale del trading swing è di individuare una tendenza e quindi capitalizzare su salti e picchi che forniscono punti di ingresso. Uno swing trader utilizzerà l’analisi tecnica per identificare questi punti di prezzo chiave. Una fluttuazione verso valori bassi indica l’opportunità di acquistare in una posizione lunga o vendere una posizione corta, mentre una verso valori alti è un’opportunità per vendere una posizione lunga o aprire una posizione corta.
Day trading: è uno stile che specifica che un trader aprirà e chiuderà tutte le loro posizioni prima che i mercati chiudano ogni sera. I day trader compreranno e venderanno più attività nel giorno di negoziazione, o talvolta più volte al giorno, per trarre vantaggio dai movimenti del mercato a breve termine.
Scalping: è uno stile di trading che prevede l’apertura e il mantenimento di una posizione per un periodo di tempo molto breve, da pochi secondi a qualche minuto al massimo. L’idea alla base di questa strategia è di aprire una trade e di chiuderla non appena il mercato diviene favorevole, implicando profitti frequenti ma esigui. Può essere considerata come una versione più rapida e intensa del day trading.
Le bande di Bollinger sono degli intervalli sfruttati nell’ambito finanziario, per poter misurare e studiare la componente casuale che influisce sull’andamento dei mercati, la cosiddetta volatilità. Questa può essere vista come la deviazione standard del valore di un titolo, ovvero come la fluttuazione media in un dato intervallo temporale.
Quando si effettuano transazioni, è importante valutare anche questa componente, per poter avere una visione più chiara sugli eventuali rischi legati ad un certo titolo. Le bande di Bollinger sono state teorizzate proprio per riuscire a studiare in maniera più accurata questa componente per sua natura imprevedibile.
Esse vengono calcolate innanzitutto attraverso una media mobile a G giorni (spesso 20). Le bande estreme (ovvero gli estremi degli intervalli) sono ottenute aggiungendo o sottraendo il valore della deviazione standard moltiplicata per un determinato fattore F (spesso 2). In dettaglio, la banda superiore è quindi ottenuta aggiungendo alla media mobile F volte la deviazione standard, la banda inferiore sottraendo F volte la deviazione standard e la banda centrale è la media mobile stessa.
Ad un’ampiezza maggiore delle bande corrisponde una maggiore volatilità. Questo bande permettono di analizzare situazioni in cui il prezzo diventa favorevole ad una vendita o ad un acquisto. Ad esempio, se l’andamento del prezzo esce dalla banda superiore e successivamente vi rientra, si ottiene un segnale di vendita, poiché il prezzo è aumentato rapidamente al di fuori delle fluttuazioni ritenute casuali; quando invece il grafico del prezzo esce dalla banda inferiore e successivamente vi rientra, si ottiene un segnale di acquisto, poiché il prezzo è calato molto velocemente fino ad arrestarsi e, probabilmente, ad invertire il trend.
In statistica, la media mobile è uno strumento utilizzato per l’analisi di serie storiche. In particolare, le medie mobili vengono ampiamente utilizzate nell’analisi tecnica. Viene definito come una media pesata di più termini, centrata solitamente sul valore di riferimento. In formule, data una serie storica contenenti i valori osservati di una variabile Y dal tempo 1 al tempo T, la media mobile è definita come:
dove:
è il numero di giorni precedenti a t;
è il numero di giorni successivi a t;
è il peso da attribuire all’i-esimo valore osservato;
è il periodo o l’ordine della media mobile, ed equivale al numero degli addendi.
Esistono diversi tipi di medie mobili, che possono essere definite o dai valori assunti dalle diverse componenti o dalla formula di derivazione utilizzata. Ad esempio, se i pesi sono tutti pari ad 1 si parla di media mobile semplice (ed equivale ad una semplice media aritmetica). Se invece il numero di giorni successivi a t risulta essere pari al numero di giorni precedenti, si parla di media centrata. Una media mobile è centrata e simmetrica se per ogni m e .
Alcune delle medie mobili definite da diverse tipologie di calcolo sono invece: (i) la media mobile semplice (SMA), probabilmente la più utilizzata ed intuitiva, dove vengono presi i dati di un determinato periodo e ne viene calcolata la media sommandoli fra loro e dividendo per il numero totale di valori, dando quindi la stessa importanza ad ogni valore osservato; (ii) la media mobile ponderata (WMA), ideate per ovviare al problema riguardante l’utilizzo del medesimo peso per ogni osservazione nella SMA e dove, infatti, prendendo in esame una media mobile a 10 periodi, la chiusura del decimo giorno viene moltiplicata per 10, quella del nono giorno per nove, dell’ottavo giorno per otto e così via, dando priorità alle osservazioni più recenti a scapito di quelle più lontane; (iii) la media mobile esponenziale (EMA) che viene generata da un sistema di calcolo molto più complesso che cerca sempre di eliminare le carenze della media mobile semplice.
In generale, una media mobile risulta essere molto utile quando si cerca di analizzare il trend di una serie storica, poiché essa riesce a ridurre fortemente le fluttuazioni casuali che si possono verificare. Se infatti si fa un confronto tra una serie storica e la stessa dopo l’applicazione di una media mobile, è possibile vedere come la seconda risulti essere molto più regolare e con valori più stabili, dando una più chiara visione delle componenti a lungo termine e non casuali che compongono un processo.
In VB.NET e in C# esistono metodi che permettono la manipolazione di eventi da diversi punti di vista. In questo articolo ne vedremo, nello specifico, tre:
Timer: permette la creazione di un timer con cui gestire l’attivazione di determinate azioni;
Background worker: consente di dedicare un thread all’esecuzione di alcune specifiche operazioni;
Extention method: metodi aggiunti a degli oggetti dopo la creazione originaria di essi.
Più nel dettaglio, gli elementi precedente elencati hanno le seguenti caratteristiche:
La classe timer consente l’implementazione di un timer che può avere molteplici utilizzi. In maniera “passiva” può essere utilizzato per controllare l’effettivo tempo di esecuzione di una operazioni o di un intero programma. In questo modo diventa possibile il confronto del tempo impiegato, ad esempio, da algoritmi diversi che producono lo stesso risultato, permettendo di scegliere il più efficiente (in termini di tempo richiesto, ovviamente). In maniera “attiva” un timer può essere introdotto per la gestione di eventi a intervallo in un’applicazione. Questo fornisce molteplici vantaggi, permettendo di attivare una determinata routine senza la necessità che l’utente la richiami direttamente, ma associandola, ad esempio, ad un determinato lasso temporale.
Il background worker consente di eseguire un’operazione su un thread separato. Questo può rivelarsi essere molto utile, in quanto consente al programma di continuare l’esecuzione, senza dover necessariamente aspettare che operazioni molto lente (il cui risultato potrebbero essere necessario solo ad un punto più avanzato del programma) blocchino l’intera esecuzione. Si può applicare, ad esempio, ad operazioni come download e transazioni di database. In sostanza, l’interfaccia utente ed il programma rimangono attivi, nonostante siano in esecuzione delle operazioni (cosa che solitamente implica la disattivazione di questi ultimi). È possibile creare il BackgroundWorker in due diversemaniere: (i) a livello di codice; (ii) trascinandolo sul form dalla scheda componenti della casella degli strumenti. Se lo si crea nella progettazione Windows Form, questo verrà visualizzato nella barra dei componenti e le relative proprietà verranno visualizzate nella Finestra Proprietà, semplificandone la gestione.
Gli extension method (metodi di estensione) sono metodi che consentono di aggiungere funzionalità ad un oggetto una volta che esso è stato creato, senza la necessità di creare una nuova classe che implementi tutte le caratteristiche richieste. I metodi di estensione permetto la scrittura di un metodo la cui chiamata sarà identica alla chiamata di un metodo di istanza del tipo esistente. Può essere solo una routine Sub o una procedura Function. Tutti i metodi di estensione vengono indicati dalla dichiarazione Extension durante la creazione degli stessi e devono essere definiti in modulo.
Il Profit and Loss (P&L) è una funzione del tempo che dipende dalle transazioni eseguite e dal prezzo degli strumenti su cui vengono eseguite queste transazioni al momento delle transazioni. Indica i guadagni e le perdite di un certo intervallo temporale. In generale, è dato dalla differenza tra il prezzo di vendita (sell) e di acquisto (buy) dello strumento finanziario considerato al momento in cui vengono eseguite tali operazioni, differenza che viene moltiplicata per la quantità scambiata (Q) e per un opportuno moltiplicatore (M) associato allo strumento considerato. La formula per quantificare il P&L è quindi la seguente:
dove e rappresentano il prezzo di vendita e il prezzo di acquisto e sono rappresentati, rispettivamente, sulla curva bide nella curva ask.
Il Profit and Loss (P&L) indica i guadagni e le perdite relative ad un certo periodo di tempo limitato. È una funzione del tempo e dipende dalla strategia applicata e dai prezzi degli strumenti acquistati e/o venduti previsti dalla strategia stessa. Il PNL è dato dalla differenza tra il prezzo sell ed il prezzo buy il tutto moltiplicato per la quantità scambiata (assumendo che la quantità venduta ad acquistata sia la stessa) ed eventualmente anche per il moltiplicatore associato allo strumento considerato . Nel PNL dovrà essere considerata anche la commissione, ovvero prezzo dell’operazione che rappresenta una perdita immediata ed inevitabile.
Il P&L può essere separato in unrealized P&L e realized P&L. L’unrealized P&L si calcola valutando il profitto o la perdita virtuali derivanti da una posizione ancora aperta, ma che viene considerata chiusa al valore corrente del mercato. Il realized P&L invece fa riferimento alla perdita o al profitto effettivo derivante da una posizione chiusa. Il realized P&L può essere una realized loss nel caso in cui il prezzo di vendita di uno strumento finanziario risulta essere inferiore al prezzo di acquisto dello stesso, ovvero quando uno strumento finanziario viene venduto ad un prezzo inferiore di quello di acquisto, oppure quando si vende uno strumento finanziario ad un prezzo inferiore a quello rispetto ad un successivo riacquisto dello stesso. In modo contrario, invece, se il prezzo di acquisto risulta essere inferiore al prezzo di vendita dello strumento finanziario in considerazione, oppure si riacquista uno stesso strumento finanziario ad un prezzo inferiore al precedente prezzo di vendita, si parla di realized profit.
Nella realizzazione di una strategia di marketing, quando sono considerati più ordini di acquisto e vendita, bisogna stabilire una strategia per l’esecuzione del matching degli ordini. Esistono diversi metodi, con gradi di complessità diversi, che producono effetti molto diversi in termini di unrealized e realized P&L. Le principali strategie sono:
In finanza l’incertezza gioca un ruolo chiave e la capacità di modellare questa e di saperla in qualche modo prevedere è un fattore fondamentale quando si operano investimenti. Per molti strumenti finanziari, soprattutto quelli relativi alle materie prima (commodities), la fluttuazioni del prezzo attorno ad un valore di equilibrio non riesce ad essere modellato da un moto Browniano. Questo infatti presenta un a varianza troppo elevata, non implicando che la variazione delle fluttuazioni porti i valori ad essere troppo distanti (in maniera inverosimile) dai prezzi di equilibrio. Nasce da questo limite i cosiddetti modelli mean reversion. La mean reversion è una notissima strategia di trading usata soprattutto nel mercato azionario ma applicabile anche ad altri mercati finanziarii. L’idea di fondo si basa appunto sul fatto che il prezzo massimo e il prezzo minimo di un titolo siano temporanei, e che esso tenderà invece ad avere un prezzo di equilibrio nel tempo. Essa si applica dapprima identificando l’intervallo di trading dell’azione e poi calcolando il prezzo medio usando tecniche analitiche. L’idea di fondo è che quando il prezzo dell’azione nel mercato attuale è inferiore a tale prezzo medio, il titolo è considerato attraente per l’acquisto, poiché ci si aspetta che il prezzo salga. Quando, viceversa, il prezzo attuale del mercato è superiore al prezzo medio dell’azione, ci si aspetta che il prezzo del titolo cali: in altre parole, ci si attende che le deviazioni dal prezzo medio riportino il prezzo all’equilibrio.
In questo scenario, il modello più semplice è il processo di Ornstein-Uhlenbeck. Il processo di Ornstein-Uhlenbeck è un processo stocastico originariamente sviluppato per modellare la velocità di una particella Browniana sottoposta ad un determinato attrito, trovando poi applicazione, appunto, nella matematica finanziaria. Può essere visto come una variazione della random walk in tempo continuo (o del processo di Wiener), dove le proprietà del processo sono cambiate in maniera tale che la camminata aleatoria tenderà a tornare verso un valore centrale di equilibrio, con un attrazione maggiore all’aumentare dalla distanza dal punto di equilibrio.
Il processo è definito dalla seguente equazione stocastica differenziale:
dove rappresenta la reversion speed, ovvero la velocità (o intensità) con cui il processo tenderà al punto di equilibrio, che risulta essere pari a 0, è il valore del processo di Ornstein-Uhlenbeck al tempo t e è il processo di Wiener. Maggiore sarà quindi la distanza del valore dallo 0, più forte sarà la tendenza a tornare verso l’equilibrio.
Da questo processo è possibile ricavare in maniera immediata il modello di Vasicek, aggiungendo una costante come valore di equilibrio al quale il processo tenderà, trasformando l’equazione precedente come segue:
Il modello Vasicek è un modello matematico che descrive, in finanza, l’evoluzione dei tassi di interesse. È un tipo di modello ad un fattore a tasso breve, in quanto descrive le variazioni dei tassi di interessi come causati da una sola fonte di rischio di mercato. Questo modello può essere utilizzato nella valutazione dei derivati sui tassi di interesse. È stato il primo modello a catturare l’inversione media, una caratteristica essenziale del tasso di interesse che lo distingue dagli altri prezzi finanziari. A differenza dei prezzi delle azioni, ad esempio, i tassi di interesse non possono aumentare indefinitamente. Questo perché a livelli molto alti ostacolerebbero l’attività economica, provocando una riduzione dei tassi di interesse. Di conseguenza, la variazione dei tassi di interesse avviene in un intervallo limitato e, solitamente, tendono a tornare ad un valore di equilibrio a lungo termine.
Il processo di Poisson è un processo stocastico che simula il manifestarsi di eventi che siano indipendenti l’uno dall’altro e che accadano continuamente nel tempo. Si tratta quindi di un processo a tempo continuo, ma definito su uno spazio discreto ed è il processo più utilizzato per processi di conteggio. Viene utilizzato sopratutto per scenari in cui è necessario contare degli eventi che occorrono con una certa frequenza e in modo completamente randomico (la distribuzione di Poisson che, come si può intuire dal nome, è alla base del processo di Poisson, è non a caso anche chiamata legge degli eventi rari). Alcuni esempi pratici di scenari modellabili attraverso un processo di Poisson o sue trasformazioni sono:
il numero di incidenti stradali in una data area geografica;
la posizione degli utenti connessi in una rete wireless;
la richiesta dei singoli documenti in un web server;
lo scoppio di guerre;
l’avvenimento di terremoti.
Il processo di Poisson soddisfa le seguenti proprietà:
, ovvero il numero di eventi osservati al tempo 0 deve essere pari a 0 (parte dall’origine);
la probabilità che avvenga un evento in un intervallo di tempo infinitesimale è proporzionale alla lunghezza stessa dell’intervallo, ovvero ;
la probabilità che non avvenga nessun evento in un intervallo di tempo infinitesimale è proporzionale alla lunghezza stessa dell’intervallo, ovvero ;
la probabilità che avvenga più di un evento in un intervallo di tempo infinitesimale è trascurabile, ovvero ;
il numero di eventi contati in intervalli di tempo disgiunti sono indipendenti, ovvero le variabili aleatorie sono indipendenti per ogni .
Il legame di questo processo con la distribuzione di Poisson lo si invece se si considera la generica soluzione della probabilità che, ad un determinato tempo t, siano stati osservati k eventi, che risulta essere pari a:
che è esattamente pari alla funzione di densità della distribuzione di Poisson di parametro per k eventi.
La distribuzione di Poisson gode di alcune importanti proprietà. Ad esempio, la distribuzione di Poisson di parametro si può ottenere come limite per di una distribuzione binomiale. Fissiamo . La distribuzione binomiale di parametri e , dove è il numero di prove effettuate e è la probabilità di successo, ha legge di probabilità:
da cui, possiamo ottenere:
Si può dimostrare facilmente, sviluppando il fattoriale, che questa equivale a:
Come è noto, per , perciò è dimostrato il limite.
Un’altra distribuzione legata a quella di Poisson è la distribuzione binomiale negativa. Questa infatti è la legge di distribuzione che regola i tempi di attesa tra due eventi successivi in un processo di Poisson. In particolare, in un processo di Poisson di parametro il tempo di attesa tra due eventi successivi sarà distribuito proprio come una binomiale negativa di parametro .
Un moto Browniano geometrico (anche conosciuto come moto Browniano esponenziale), è un processo stocastico ad indice continuo.La particolarità di questo processo è che il logaritmo degli incrementi si comportano come un moto Browniano standard.
Questo processo è stato teorizzato per sopperire ai limiti del moto Browniano aritmetico, che procede per incrementi additivi. Questo, in uno scenario come quello finanziario, comporta delle problematiche importanti, come la possibilità di ottenere, ad un tempo t, dei prezzi negativi, nonostante il punto di partenza venga scelto estremamente elevato. Inoltre, il moto Browniano, nella sua forma additiva, risulta inadeguato a modellare tassi di incremento, che di per sé necessitano di un modello moltiplicativo, essendo definiti come:
.
R è detto tasso di incremento oreturn.Si può quindi considerare un modello additivo per esprimere l’incremento dei prezzi, ricavandone la successiva equazione differenziale, riportate entrambe qui di seguito:
.
Essendo il differenziale un prodotto, la derivazione della distribuzione degli incrementi non è più immediata come nel caso di una somma di normali. In questo contesto, vengono in aiuto le proprietà dei logaritmi. Usando questa trasformazione è possibile infatti esprimere un prodotto come una sommatoria. L’equazione differenziale, dopo la trasformazione logaritmica, risulterà quindi essere:
.
Si ottiene quindi nuovamente una somma di normali. In questo modo è possibile agilmente verificare che si distribuisce come una normale, di conseguenza P avrà distribuzione log-normale. In questo modo vengono meno tutti i problemi inizialmente elencati, poiché non potrà assumere valori negativi e potrà modellare relazioni moltiplicative e non solo additive, ampliando gli scenari finanziari studiabili attraverso il moto Browniano. Concludendo, in maniera intuitiva, il moto Browniano geometrico serve per situazioni in cui non è tanto il valore stesso ad avere una distribuzione casuale, quanto i suoi incrementi, ed in cui i valori che possono essere assunti sono strettamente positivi. Un esempio concreto potrebbe essere il valore di una moneta ad un dato tempo rapportata al valore di una moneta ad un tempo precedente preso come riferimento (l’indice dei prezzi al consumo). In questo caso la moneta tenderà ad aumentare di valore nel corso del tempo, a causa dell’inflazione, aumentando di una percentuale ogni anno e causandone una sorta di aumento esponenziale. Inoltre il valore dovrà essere strettamente positivo poiché, anche se gli incrementi possono avere segno negativo (si parla in questo caso di decrementi), la moneta dovrà mantenere un valore strettamente maggiore di 0.
In matematica, un processo di Wiener, conosciuto anche come moto browniano, è un processo stocastico gaussiano in tempo continuo con incrementi indipendenti, usato per modellizzare il moto browniano stesso e diversi fenomeni casuali osservati nell’ambito della matematica applicata, della finanza e della fisica. In matematica applicata, il processo di Wiener è usato per rappresentare l’integrale del rumore bianco gaussiano; ed è molto utile come modello del rumore in ingegneria elettronica, nella teoria dei filtri e per rappresentare gli ingressi sconosciuti nella teoria dei controlli.
Prendendo in considerazione il processo di Wiener standard, esso è caratterizzato dalle seguenti condizioni:
;
le traiettorie descritte sono continue quasi certamente;
il processo è definito ad incrementi indipendenti, ovvero considerando una successione non decrescente di tempi allora le variabili aleatorie definite come sono tra loro indipendenti;
il processo ha incrementi gaussiani, ovvero dati due tempi allora .
Da questa prima definizione, è possibile poi ottenere il processo di Wiener generalizzato, in cui gli incrementi non sono più distribuiti come una normale , ma sono distribuiti secondo una normale di media e varianza scalata per un fattore ..
In questo contesto, prendendo in considerazione dei prezzi, è possibile generalizzare gli incrementi relativi ad un processo di Wiener standard con la seguente formula
dove è distribuito come una normale .
Con una formula molto è possibile rappresentare gli incrementi derivanti da un processo di Wiener generalizzato, dove gli incrementi sono appunto distribuiti come una normale , rappresentandoli attraverso opportune trasformazioni di incrementi distribuiti secondo una normale :
Questi incrementi, dato che nel moto Browniano sono variabili assolutamente continue, possono essere rappresentati anche attraverso equazioni differenziali, con incrementi infinitesimali. Queste equazioni prendono il nome di Stochastic Differential Equations (SDE). Le formule per il processo di Wienerstandard e per il processo di Wienergeneralizzato sono, rispettivamente:
Il moto Browniano è sicuramente una delle scoperte più importanti del secolo scorso. Inizialmente modellato per descrivere la traiettoria di particelle sufficientemente piccole in dei fluidi, si è subito visto come la sua reale applicazione potesse essere estesa ai più diversi ambiti, tra cui anche e sopratutto la finanza.
A differenza della random walk, il moto Browniano viene indicizzato su tempi continui e a valori reali, indicando con . In quest’ultimo, gli spostamenti infinitesimali sono distribuiti come una gaussiana. Inoltre presenta diverse proprietà fondamentali, quali:
, ovvero il valore del moto Browniano al tempo 0 è pari al punto di partenza considerato;
le traiettorie descritte sono continue quasi certamente;
il processo è definito ad incrementi indipendenti, ovvero considerando una successione non decrescente di tempi allora le variabili aleatorie definite come sono tra loro indipendenti;
se si considera il moto browniano semplice, senza deriva, allora vale anche che per ogni coppia di valori , gli incrementi sono distribuiti secondo una gaussiana di media e di varianza .
Questa scoperta vede inizialmente la sua applicazione in ambito fisico, per poi estendersi a molti altri campi. Le proprietà del moto Browniano permettono infatti di modellare diversi fenomeni casuali. Una sua applicazione importantissima fu dimostrata nel 1900 da un noto matematico francese, Louis Bachelier. Egli dimostrò, nella sua tesi di dottorato, un approccio statistico per modellare l’andamento dei prezzi dei titoli alla Borsa di Parigi. Per fare ciò, utilizzò una variazione dei metodi utilizzati da Einstein per analizzare il moto Browniano, prendendo le principali proprietà precedentemente descritte.
A partire dagli anni sessanta, questo processo ha visto un suo più ampio utilizzo, sotto forma della “versione migliorata” di questa teoria, rappresentata dal processo di Wiener.
Un altro studioso, a cui si deve il merito di un progresso nell’ambito finanziario, fu Osborne che nel 1964 formalizzò un modello Random Walk per l’andamento delle azioni. In particolare, egli elaborò un processo in base al quale le variazioni dei prezzi delle azioni potevano essere equivalenti al moto di una particella in un fluido, ciò e al moto Browniano.





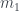
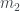









 (assumendo che la quantità venduta ad acquistata sia la stessa) ed eventualmente anche per il moltiplicatore associato allo strumento considerato
(assumendo che la quantità venduta ad acquistata sia la stessa) ed eventualmente anche per il moltiplicatore associato allo strumento considerato  . Nel PNL dovrà essere considerata anche la commissione, ovvero prezzo dell’operazione che rappresenta una perdita immediata ed inevitabile.
. Nel PNL dovrà essere considerata anche la commissione, ovvero prezzo dell’operazione che rappresenta una perdita immediata ed inevitabile.




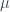










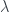



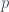





 .
.

 .
.
 .
.