I tipi numerici a “precisione arbitraria” (conosciuti anche come interi a “precisione infinita” o bignum), permettono la rappresentazione del numero attraverso uno spazio mutevole di memoria, aumentando enormemente il range di rappresentazione del numero. L’unico limite si pone, infatti, per la finitezza della memoria del computer. Tuttavia, con 8 KB di memoria, si può arrivare a rappresentare numeri di 2466 cifre.
Alcuni linguaggi supportano direttamente i numeri a precisione arbitraria. In altri linguaggi è invece necessario importare delle apposite librerie. La libreria System.Numerics contiene una classe BigInteger i cui oggetti possono rappresentare numeri interi di lunghezza arbitraria. Questi oggetti non utilizzare i classici operatori aritmetici ( + * – / =), ma è necessario utilizzare i metodi forniti dalla classe stessa, che sono: add, multiply, subtract, equals. Per poter inizializzare i numeri BigInteger, è necessario utilizzare un metodo Parse per poter assegnare l’intero arbitrario come stringa. Questo è necessario poiché altrimenti non sarebbe possibile rappresentare numeri di queste dimensioni.
Il fattoriale di un numero n, indicato con la simbologia n!, rappresenta il prodotto di tutti gli interi da 1 fino al numero n compresi, ovvero:
Il calcolo del fattoriale seguendo la formula canonica può rivelarsi essere molto lungo e molto esigente, dal punto di vista del costo computazionale. Tuttavia esistono diversi algoritmi che permettono il calcolo del fattoriale in un minor lasso di tempo. I principali sono:
SpliRecursive: è l’algoritmo più rapido che non utilizza la fattorizzazione in primi ed è relativamente semplice da implementare;
PrimeSwing: è l’algoritmo conosciuto asintoticamente più veloce per calcolare n!; si basa sul concetto di “Swing Numbers”, calcolando il fattoriale tramite la scomposizione in fattori primi;
Poor Man’s: questo algoritmo non utilizza nessuna libreria Big-Integer, può essere facilmente implementato su qualsiasi computer ed è rapido fino a 10000 fattoriale.
ParallelPrimeSwing: corrisponde all’algoritmo PrimeSwing con prestazioni migliorate grazie a metodi di programmazione concorrenti e sfruttando così processori multipli.
In programmazione la gestione degli errori è il processo di risposta all’occorrenza di exceptions, che sono condizioni anomale o speciali che richiedono una gestione speciale. Queste eccezioni (o errori) vengono “lanciate” automaticamente dal compilatore quando si imbatte in problemi che interrompono la normale esecuzione del programma (come, ad esempio, overflow). In poche parole, quando si verifica un imprevisto, il metodo attivo “lancia” (throw) un’eccezione che viene passata al metodo chiamante. Il metodo attivo termina quindi l’esecuzione. Per default, un metodo che riceve un’eccezione termina l’esecuzione e passa l’eccezione al metodo chiamante. Quando l’eccezione raggiunge il metodo main (ovvero il metodo principale), l’esecuzione del programma termina stampando un opportuno messaggio di errore.
Tuttavia, è possibile gestire gli errori in maniera tale da non interrompere il programma e gestendo anche la stampa del messaggio di errore, lasciando al programmatore la possibilità di gestirlo nella maniera più consona. La struttura Try, Catch serve esattamente a questo. Si compone da due blocchi di comandi, più un terzo non obbligatorio, che hanno le seguenti funzioni:
il blocco Try contiene le istruzioni da eseguire, che potrebbero generare eccezioni e che si vuole controllare;
il blocco Catch contiene la gestione degli errori che potrebbero essere generati durante l’esecuzione del Try (è possibile aggiungere più blocchi Catch per gestire separatamente le diverse tipologie di eccezioni che il Try può generare);
il blocco Finally può, facoltativamente, essere messo alla fine e comprende il blocco di istruzioni da eseguire indipendentemente dall’esito delle istruzioni contenute nel blocco Try.
La sintassi del Try, Catch per quanto riguarda C# e VB.NET è la seguente:
Il blocco Try, Catch funziona abbastanza linearmente; vengono eseguite le istruzioni contenute nel Try. Se l’esecuzione procede senza aver generato nessun errore, vengono eseguite le istruzioni presenti nel Finally (se presente) e il programma prosegue con la prima istruzione dopo il blocco Try, Catch. Se invece vengono generate delle eccezioni durante il Try, l’esecuzione termina alla prima istruzione che genera errore(le istruzioni successive a quella incriminata non vengono quindi eseguite) e viene eseguita la gestione presente nel blocco Catch relativo al tipo di errore generato (può anche darsi che il Catch gestisca qualsiasi generico errore, non è necessario specificare un Catch per ogni errore che potrebbe essere generato). Infine vengono comunque eseguite le istruzioni nel Finally.
Si può gestire un’eccezione anche in maniera più “pigra”, inserendo nella definizione del metodo una “throw exception“. Questo comando in sostanza significa che il metodo appena eseguito potrebbe generare una eccezione e che il metodo chiamante deve occuparsi della sua gestione.
In C# e VB.NET il comportamento delle eccezioni non gestite è leggermente differente:
in C# l’ultimo metodo chiamante che non comprende il comando “throw exception” deve gestire l’eccezione con un blocco Try, Catch;
in VB.NET: è presente un gestore di eventi (“Eccezione non gestita”) che consente, , di intercettare l’eccezione in cima alla pila e di definire la sua gestione.
Quando si scrive un programma, è essenziale ricordare che potrebbe essere riletto numerose volte, ed eventualmente anche modificato. Si rende quindi necessario scrivere un codice facilmente leggibile da tutti, per poter comprendere cosa il codice fa in minor tempo. In questo contesto nascono le convenzioni sui nomi, che forniscono uno standard nella scrittura dei programmi. Tra le diverse convenzioni sui nomi adottate dai programmatori, le più diffuse sono:
Camel Case
Pascal Case
Snake Case
Kebab Case
Screaming Case
Hungarian Notation
Prima di vedere nel dettaglio le diverse convenzioni, occorre sottolineare che esse vengono divise in due macro-categorie:
Tipografiche: Fa riferimento all’uso delle diverse dimensioni del carattere e ai simboli quali trattino basso, punto e trattino.
Grammatiche: Fa riferimento alla semantica e allo scopo. Ad esemio, le classi dovrebbero essere sostantivi o frasi nominative per identificare l’entità, i metodi e le funzioni dovrebbero essere verbi per identificare l’azione compiuta.
Camel case
Il camel case (o notazione a cammello) nasce dalla pratica di scrivere parole composte o frasi unendo tutte le parole tra loro, ma lasciando le loro iniziali maiuscole. Il nome deriva dai “salti” all’interno di una parola, che fanno venire in mente le gobbe di un cammello. Alcuni esempi famosi di questa convenzione sono “FedEx”, “iPhone” e “eBay”. Questa convenzione viene ad esempio adottata da Java, che utilizza la forma con le iniziali maiuscole per specificare le classi e la forma con le iniziali minuscole per specificare gli oggetti.
Pascal case
Può essere considerato una sottocategoria del camel case dove le parole devono rigorosamente iniziare con una lettera maiuscola. Ad esempio, “FedEx” è in pascal case, ma “iPhone” non lo è. Questa convenzione viene adottata, ad esempio, dal linguaggio Pascal, da cui deriva anche il nome del pascal case.
Snake case
Lo snake case consiste nello scrivere gli identificatori separando le parole che lo compongono con un trattino basso, solitamente lasciando minuscole le iniziali delle parole e la prima lettera dell’intero identificatore minuscola o maiuscola (ad esempio “foo_bar” e “Hello_world”). Viene ampiamente utilizzato in programmazione e studi dimostrano che è sia più leggibile rispetto il camel case. Viene utilizzato da diversi linguaggi, come C, C++ e Python.
Kebab case
Molto simile allo snake case, consiste nello scrivere gli identificatori separando le parole che lo compongono con dei trattini (ad esempio “kebab-case”). Ovviamente questa convenzione può essere usata solo in quei linguaggi che ammettono il trattino come carattere valido in un identificatore (ad esempio non è ammesso in C ed i suoi derivati). Viene comunemente utilizzato da linguaggi come ad esempio Forth, Cobol , Lisp e CSS.
Screaming case
Questa convenzione ha essenzialmente due varianti, molto simili: la prima consiste nello scrivere le parole tutte in maiuscolo e senza spazi (ad esempio “TAXRATE”); la seconda invece prevede la separazione delle diverse parole che compongo l’identificatore tramite un trattino basso, lasciando sempre le parole tutte in maiuscolo (ad esempio “TAX_RATE”), motivo per il quale viene chiamato anche screaming snake case. Il nome (letteralmente caso urlato) deriva dal fatto che, convenzionalmente, su internet la scrittura di tutta una parola in maiuscolo equivale ad urlare.
Hungarian notation
La hungarian notation (in italiano notazione ungara o notazione ungherese) è una convenzione in cui il nome dell’oggetto indica il suo tipo e il suo scopo d’uso. È stata progettata in maniera tale da essere indipendente dal linguaggio. Nella hungarian notation, un nome di variabile inizia con un prefisso costituito da una o più lettere minuscole in modo da formare un codice mnemonico per il tipo o lo scopo di questa variabile. Il prefisso è seguito dal nome scelto dal programmatore. Il primo carattere del nome assegnato è in maiuscolo come nel camel case.
Alcuni esempi dell’hungarian notation sono i seguenti:
Per poter gestire più oggetti dello stesso tipo, abbiamo visto che è possibile utilizzare strutture come gli array. Tuttavia, essi hanno un limite che può complicare notevolmente il loro utilizzo. Infatti, bisogna dichiarare in precedenza il numero di elementi che verranno trattati, compito che a volte risulta impossibile, soprattutto quando si vanno a trattare dati di grande dimensione ed è impossibile stabilire la quantità massima di elementi che verranno salvati. Con il tempo sono state sviluppate diverse alternative che permetto di superare questi ed altri limite: liste e dizionari.
Liste
Una lista è una struttura dati dinamica che denota una collezione omogenea di dati. Contrariamente agli array, la memoria utilizzata non è necessariamente contigua. L’accesso ad un elemento avviene attraverso l’utilizzo di un indice. A seconda del linguaggio utilizzato, le liste possono essere indicizzate a partire da 0 (come in VB.net) o a partire da 1 (come in C#). Tuttavia, solitamente l’accesso agli elementi di una lista avviene in maniera diretta solo per il primo elemento della sequenza ; per accedere a un qualunque elemento, occorre scandire sequenzialmente tutti gli elementi che lo precedono. La particolarità di questa struttura è che, contrariamente agli array tradizionali, non è necessario specificare la dimensione in dichiarazione, ma varierà a seconda del numero di elementi inseriti. In VB.net e in C# sono dichiarate con le seguenti sintassi:
VB.net
Dim NameList As New List(Of DataType)
C#
List<dataType> nameList = new List<dataType>();
Dizionari
I dizionari sono strutture dati che denotano una collezione di dati. Come le liste, la loro dimensione non deve essere specificata in fase di dichiarazione, ma sarà stabilita dinamicamente in base al numero di elementi al suo interno. Un’altra peculiarità di questa struttura è la possibilità di accedere agli elementi attraverso una chiave stabilita direttamente dal programmatore. Infatti, questa struttura è caratterizzata dall’inserimento dei valori attraverso la coppia chiave-valore, dove ogni chiave può comparire al più una sola volta. Le operazioni ammesse su un dizionario sono:
l’inserimento di una nuova coppia
la rimozione di una coppia dalla collezione
la modifica di una coppia esistente
la ricerca di un particolare valore associato ad una determinata chiave
In VB.net e in C# viene dichiarata con la seguente sintassi:
VB.net
Dim NameDictionary As New Dictionary(Of TypeKey, TypeValue)
C#
Dictionary<typeKey, typeValue> nameDictionary =
new Dictionary<typeKey, typeValue>();
La finitezza nella rappresentazione dei numeri reali all’interno di un computer può portare a diversi tipi di errori. Da una parte, la limitazione nella dimensione dei numeri può comportare errori quali overflow e underflow, ovvero quando il numero eccede il limite massimo o il limite minimo di rappresentazione della variabile in cui viene salvato (la dimensione delle diverse variabili numeriche è descritta meglio nell’articolo sulla rappresentazione dei tipi Float e Integer).
Altri possibili errori sono legati alla precisione finita dei tipi Float, che può generare errori quali: roundoff error; loss of significance (perdita di significatività) e catastrophic cancellation (cancellazione catastrofica).
Il roundoff error è dovuto alla rappresentazione di un numero reale usando un numero finito di cifre. Naturalmente più un numero è preciso e minore sarà questo errore. Questo errore è presente anche quando si cerca di esprimere numeri in base 10, poiché il computer utilizza la codifica in base 2. Questo problema può diventare particolarmente rilevante nell’ambito finanziario, in quanto, nonostante l’errore di approssimazione di questo tipo sia pressoché irrilevante se considerato singolarmente, la mole enorme di transazioni che vengono registrate può portare ad un accumulo di questi errori e stravolgendo il risultato. Per questo motivo è stato introdotto il tipo decimal, che permette la codifica dei numeri in base 10 e, quindi, una scrittura esatta dei valori delle transazioni.
La loss of significance, invece, è un errore che abbiamo quando occorre sommare (o sottrarre) due numeri molto differenti tra loro. Ad esempio, potrebbe essere necessario sommare un numero molto grande, che quindi sacrifica la precisione per aumentare la dimensione del numero, ed uno molto piccolo ma con un’alta precisione. La somma di questi numeri dovrebbe produrre un numero con sia un valore molto grande, che un’alta precisione. Tuttavia, la memoria finita comporta che il computer dovrà dedicare la maggior parte della memoria alle cifre del numero più grande, sacrificando quindi la precisione dovuta al numero più piccolo.
Infine, la catastrophic cancellation avviene quando un’operazione su due numeri comporta un aumento dell’errore relativo notevolmente più di quanto aumenti l’errore assoluto. Ad esempio, quando si sottraggono due numeri praticamente identici (ovvero che differiscono per le ultime cifre decimali), può comportare una diminuzione inaccettabile delle cifre significative. Vediamo un esempio nel dettaglio.
Consideriamo il numero:
x = 0.1234567891234567890
Se vogliamo rappresentarlo nel computer con un float con 10 cifre dopo la virgola, avremmo:
xFloat = 0.1234567891
L’errore relativo in questa approssimazione è tutto sommato irrilevante, quindi possiamo considerare questa come una buona approssimazione.
Tuttavia, se eseguiamo l’operazione:
y = 0.1234567890000000000
x-y = 0.1234567891234567890 - 0.1234567890000000000
Otteniamo come risultato:
0.0000000001234567890
Se invece operassimo questa operazione nel computer, utilizzando l’approssimazione a 10 cifre decimale proposta prima, otterremmo come risultato:
0.1234567891 − 0.1234567890 = 0.0000000001
L’errore relativo in questo caso è decisamente elevato e la perdita di cifre significative diventa molto più importante e dannosa.
Ogni dato, indipendentemente dal suo tipo, viene memorizzato in un computer con una stringa binaria. Le differenze poi sono stabilite in fase di lettura, ovvero il modo in cui una sequenza viene letta determina il valore (ed il tipo) del dato stesso. In particolare, è possibile memorizzare due tipologie diverse di dati numerici: Integer e Float.
I dati Integer rappresentano i numeri interi e, a seconda del linguaggio di programmazione, è possibile definire tipi di diverse dimensioni. I tipi interi possono ammettere segno negativo oppure essere unsigned. Esistono tre modi differenti per rappresentare i numeri negativi in un sistema binario. Il più comune è il “complemento a due”, che permette di rappresentare i numeri da -2(n-1) a 2(n-1)-1. Col complemento a due, il primo bit del numero ha peso negativo o positivo; da questo deriva che tutti i numeri che cominciano con un “1” sono numeri binari negativi, mentre tutti i numeri che cominciano con uno “0” sono numeri binari positivi.
La quantità di numeri che un Integer può rappresentare, dipende dal numero di bits da cui è composto. Un Integer con n bits può rappresentare 2n numeri. I numeri interi vengono codificati direttamente in binario.
Per i numeri Float, o a virgola mobile, la codifica è più complessa. Infatti, un numero in virgola mobile è costituito nella sua forma più semplice da due parti:
un campo significando o mantissaM;
un campo esponente e.
Un generico numero reale a può così essere rappresentato come:
Un numero è caratterizzato dal valore b, che costituisce la base della notazione in cui è scritto il numero, e la quantità p di cifre presenti nella mantissa, detta precisione.
Bisogna tuttavia sottolineare come il tipo decimal, pur essendo un Float, sia leggermente diverso dagli altri. Infatti, contrariamente a tutti gli altri tipi numerici, è codificato in base 10 (invece che nella canonica base 2). La motivazione è che questo permette di scrivere i numeri in base 10 in maniera esatta, ovvero non ricorrendo ad approssimazioni. Questo è molto utile sopratutto in ambito finanziario, in quanto le transazioni posso essere registrate con l’importo esatto, evitando così problemi legati all’approssimazione.
La tipologia di Integer, come anche di Float, definibili, dipende dal linguaggio utilizzato. Di seguito sono riportati le tipologie di numeri Integer e Float in C# e in VB.net, con il range di valori che possono assumere. Per i tipi Float viene anche riportata la precisione massima.
Quando si parla di Array (o Vettori) nell’informatica, ci si riferisce ad una struttura di dati contenenti più valori. Si può immaginare un array come una sorta di contenitore, le cui caselle sono dette celle (o elementi) dell’array stesso. Ciascuna delle celle si comporta come una variabile tradizionale; tutte le celle sono variabili di uno stesso tipo preesistente, detto tipo base dell’array. Sono molto utilizzati, in quanto semplificano enormemente la collezione di più variabili dello stesso tipo. Ciascuna delle celle dell’array è identificata da un valore di indice. È possibile accedere singolarmente ad una sua generica posizione.
A differenza delle variabili tradizionali, quando si copia un array in un secondo, non si copia il valore contenuto nelle celle dell’array, ma le coordinate che permetto di risalire a quelle celle, ovvero sono dei reference type. Le operazioni quindi fatte su una copia dell’array, verranno fatte in verità sugli elementi dell’array originale.
Sia in C# che in VB.net quando viene inizializzato un array, bisogna indicarne il tipo di variabili che verranno salvate nelle sue celle, oltre alla lunghezza dell’array stesso. La necessità di indicare preventivamente il numero (perlomeno massimo) di elementi che si intende, o prevede, salvare all’interno dell’array, crea un notevole limite, che però viene superato grazie alla classe di elementi ArryList, che in sostanza sono degli array a lunghezza variabile.
Di seguito sono riportati i codici per inizializzare un array sia in C#, sia in VB.net.
VB.net
Dim NomeArray(num) As TipoArray
C#
tipoArray[] nomeArray = new tipoArray[num];
Una fondamentale differenza nelle due sintassi riguarda il significato di num. Infatti, in VB.net, il valore di num indica il valore dell’indice dell’ultima cella, che vengono indicizzate a partire da 0. Di conseguenza, il numero di celle dell’array sarà pari a num + 1. Invece in C#, il valore di num indica la lunghezza effettiva del vettore. Inoltre gli array sono indicizzati a partire dal valore 1.
Il controllo e l’utilizzo degli array avviene spesso attraverso il ciclo for e il ciclo foreach. Entrambi sono delle strutture di controllo per specificare iterazioni.
Un ciclo for viene usato solitamente quando il modo più naturale per esprimere la condizione di permanenza in un ciclo consiste nello specificare quante volte debbano essere ripetuti l’istruzione o il blocco controllati dal ciclo. Risulta, quindi, spesso indicato per operazioni in cui è necessario scorrere tutto un array (ad esempio per copiarne i valori delle celle in un secondo array).
Il ciclo for è composto da due parti: una intestazione che specifica le condizioni delle iterazioni ed un corpo che viene eseguito se sono rispettate le condizioni. Spesso le condizioni di iterazione si basano su di un indice che viene inizializzato con valore zero e viene incrementato ad ogni iterazione (solitamente di 1) finché non raggiunge un fissato valore massimo ed a quel punto si interrompe il ciclo. Ogni operazione fatta con il ciclo for può essere riscritta con un ciclo while e viceversa.
Il ciclo foreach viene invece utilizzato quando bisogna compiere operazioni per cui non è necessario tenere un indice numerico delle iterazioni. In sostanza equivale alla frase “esegui questa operazione per ogni elemento di questo insieme”, mentre invece il ciclo for può essere parafrasato come “esegui questa operazionenvolte”. Questa differenza lo rende particolarmente adatto alle operazioni sui vettori, più del ciclo for.
Di seguito è riportata la sintassi per l’utilizzo di questi due cicli in C# e VB.net
Ciclo For
VB.net
For counter [ As datatype ] = start To end [ Step ]
[ statements ]
[ Continue For ]
[ statements ]
[ Exit For ]
[ statements ]
Next
Le strutture condizionali, anche dette strutture di controllo “alternative”, consentono di specificare che un dato blocco di istruzioni venga eseguito “(solo) se” vale una certa condizione. Le principali e più utilizzate strutture condizionali sono:
Struttura if-then e if-then-else
Struttura alternative case
Queste due strutture sono sostanzialmente molto simili. La struttura if-then (se-allora) può essere parafrasata con la frase “se vale la condizione C, allora esegui il blocco di istruzioni I“. Il controllo della condizione avviene, naturalmente, prima dell’esecuzione del blocco di istruzioni. La maggior parte dei linguaggi di programmazione ammette anche la struttura if-then-else che consiste in una catena di strutture if-then controllati in sequenza. Può essere parafrasata con la frase “se vale la condizione C esegui il blocco di istruzioni I1, altrimenti esegui il blocco di istruzioni I2“. Questa struttura può ulteriormente essere complicata aggiungendo, nel blocco else un ulteriore struttura if-then-else, permettendo quindi di controllare più condizioni in sequenza.
L’alternative case può essere visto come una catena di if-then-else con certe restrizioni. In sostanza si tratta di una struttura if-then dove il blocco di istruzioni eseguito si basa sul valore di una determinata variabile o espressione (che normalmente assume valore intero). Può essere parafrasata con la frase “valuta l’espressione N: se il suo valore è V1 esegui il blocco di istruzioni I1; altrimenti se il suo valore è V2 esegui il blocco di istruzioni I2; …” e così via con quante condizione sono necessarie.
Queste due strutture sono entrambe supportate in C# e VB.net. In entrambi i linguaggi seguono la stessa struttura, con le differenze sintattiche tipiche dei due linguaggi. Di seguito sono riportati gli esempi del codice con cui queste strutture sono scritte nei due linguaggi.
VB.net
La struttura if-then-else in VB.net è codificata come segue:
If condition [ Then ]
[ statements ]
[ Else
[ elsestatements ] ]
End If
Inoltre, in VB.net è molto semplice (e immediato) l’utilizzo di una struttura if-then-elseif-then che permette di annidiare più condizioni if insieme, interrompendo il loro controllo alla prima condizione vera trovata. Viene codificata con la seguente sintassi:
If condition [ Then ]
[ statements ]
[ ElseIf elseifcondition [ Then ]
[ elseifstatements ] ]
[ Else
[ elsestatements ] ]
End If
Naturalmente è possibile concatenare più elseif insieme.
La struttura alternative case invece segue la seguente sintassi:
Select [ Case ] testexpression
[ Case expressionlist
[ statements ] ]
[ Case expressionlist
[ statements ] ]
[ Case Else
[ elsestatements ] ]
End Select
C#
La struttura if-then-else in C# è codificata come segue:
Anche in questo caso è possibile concatenare abbastanza agilmente più condizioni if-else, anche se C# non ha una struttura dedicata appositamente a questo.
In programmazione, esistono diversi tipi di strutture di controllo iterative che consentono di specificare che una data istruzione (o blocco di istruzioni) deve essere eseguita ripetutamente sotto delle condizioni che, se false, ne consentono l’uscita. Le principali strutture di controllo iterative sono:
Ciclo for
Ciclo while
Ciclo loop-until
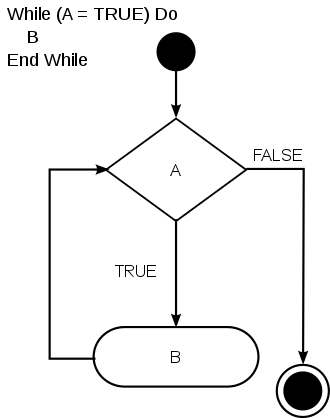
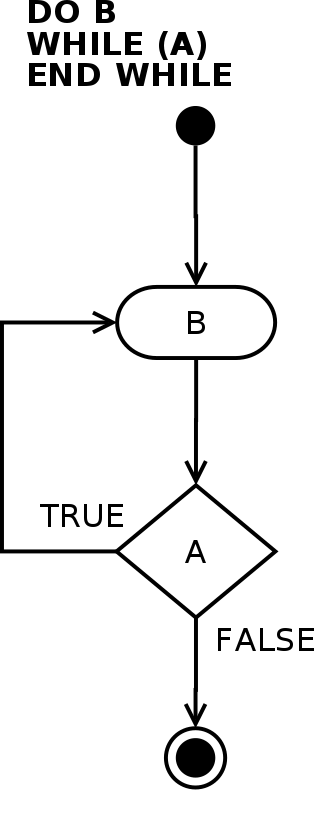
Il ciclo while, in particolare, può presentarsi con due strutture diverse: do-while e while-do. Nonostante sembrino molto simili, queste due strutture hanno una differenza importantissima. Il primo, infatti, garantisce l’esecuzione di una iterazione poiché il controllo per la permanenza nella parte iterativa avviene solo dopo l’esecuzione del blocco di comandi. La seconda struttura, di contro, prima di eseguire iterativamente il blocco di comandi, controlla che siano rispettate le condizioni di continuazione del ciclo, implicando quindi che il blocco di comandi potrebbe non essere eseguito neanche una volta.
In generale, la struttura while-do è indicata quando la condizione di permanenza in un ciclo è una generica condizione booleana, indipendente dal numero di iterazioni eseguite. Le forme tradizionali di ciclo while possono essere parafrasate come “ripeti (il codice controllato) fintantoché resta vera la condizione C“. Questa condizione, come precedentemente detto, viene controllata prima di eseguire la prima iterazione del ciclo stesso; se essa risulta immediatamente falsa, le istruzioni nel ciclo non vengono eseguite.
In C# e VB.net i cicli while presentano codifiche diverse, ma i comandi rappresentano le stesse funzioni. Di seguito sono riportati i codici nei due linguaggi per i cicli while
VB.net
Il do-while in VB.net può essere codificato in due modi diversi, ma equivalenti.
Do { While | Until } condition
[ statements ]
[ Continue Do ]
[ statements ]
[ Exit Do ]
[ statements ]
Loop
' -or-
Do
[ statements ]
[ Continue Do ]
[ statements ]
[ Exit Do ]
[ statements ]
Loop { While | Until } condition
Alternativamente, è possibile utilizzare la struttura while-do:
While condition
[ statements ]
[ Continue While ]
[ statements ]
[ Exit While ]
[ statements ]
End While
C#
Anche in C# è possibile utilizzare sia la struttura do-while, sia la struttura while-do. La struttura do-while può essere scritta come segue:
do
{
[ statements];
} while (condition);
Mentre la struttura do-while presenta la seguente struttura: