
Un processo aleatorio (o processo stocastico) è un insieme ordinato di funzioni reali di un certo parametro (in genere il tempo) che gode di determinate proprietà statistiche. In generale è possibile identificare un processo stocastico come una famiglia ad un parametro di variabili casuali reali

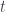
Da un punto di vista astratto, qualsiasi strumento finanziario si può considerare come una traiettoria nel tempo, ovvero come un processo stocastico parametrizzato rispetto al tempo e che, in un certo istante t, assume un certo valore

In questo contesto, la random walk è un particolare tipo di processo aleatorio, che descrive un percorso dove gli spostamenti sono regolati da una legge probabilistica ben precisa. Nella passeggiata aleatoria monodimensionale, la probabilità di uno spostamento a destra è infatti associato ad una probabilità p (propria del fenomeno che si sta studiando), e analogamente la probabilità di uno spostamento a sinistra è associato ad una probabilità pari a (1-p). Ogni passo è di lunghezza uguale e indipendente agli altri. Si può subito notare che la previsione del valore della passeggiata aleatoria ad un determinato tempo

Spostandosi in ambito finanziario, questo processo può essere utilizzato, ad esempio, per studiare l’andamento delle quotazioni in borsa, anche se altri processi aleatori (come il moto Browniano, che è simile alla passeggiata aleatoria, me ne complica notevolmente le caratteristiche) sono più adeguati allo scopo.


![[x_0, x_1 ]](https://s0.wp.com/latex.php?latex=%5Bx_0%2C+x_1+%5D&bg=ffffff&fg=333A42&s=0&c=20201002)

![(x_1, x_2 ]](https://s0.wp.com/latex.php?latex=%28x_1%2C+x_2+%5D&bg=ffffff&fg=333A42&s=0&c=20201002)

![(x_n-1, x_n ]](https://s0.wp.com/latex.php?latex=%28x_n-1%2C+x_n+%5D&bg=ffffff&fg=333A42&s=0&c=20201002)

























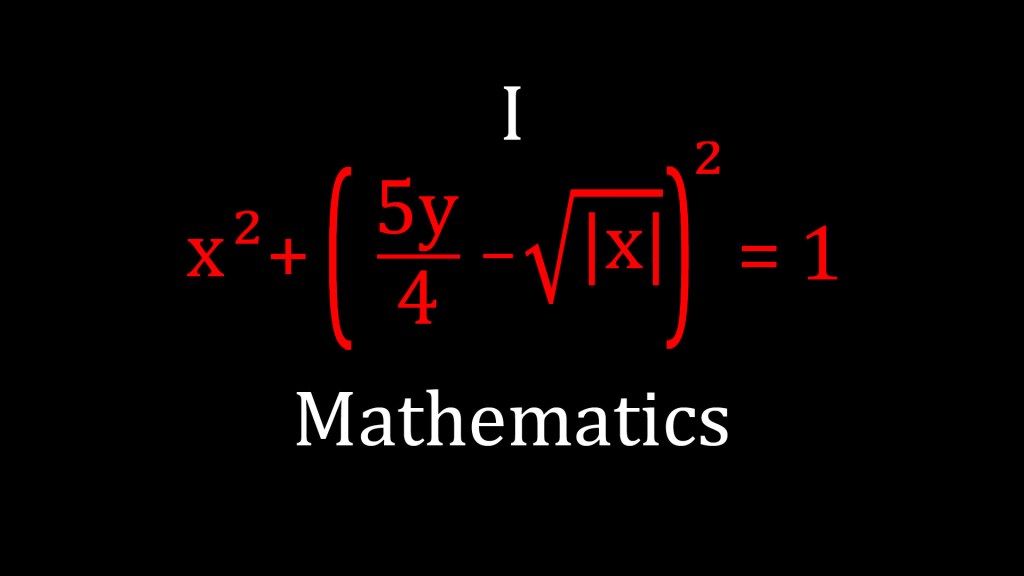












![R^2 = \frac{RSS}{TSS} = \frac{\sum_{i = 1}^{n} (y_i - \hat{y}_i)^2}{n\sigma ^2_y} = \frac{\sum_{i = 1}^{n} [\beta(x_i - \hat{x}_i)]^2}{n\sigma ^2_y} =](https://s0.wp.com/latex.php?latex=R%5E2+%3D+%5Cfrac%7BRSS%7D%7BTSS%7D+%3D+%5Cfrac%7B%5Csum_%7Bi+%3D+1%7D%5E%7Bn%7D+%28y_i+-+%5Chat%7By%7D_i%29%5E2%7D%7Bn%5Csigma+%5E2_y%7D+%3D++%5Cfrac%7B%5Csum_%7Bi+%3D+1%7D%5E%7Bn%7D+%5B%5Cbeta%28x_i+-+%5Chat%7Bx%7D_i%29%5D%5E2%7D%7Bn%5Csigma+%5E2_y%7D+%3D+&bg=ffffff&fg=333A42&s=0&c=20201002)





























![{n \choose k} = {{n!}\over{k!(n-k)!}} = {{n!}\over{(n-k)![n-(n-k)]!}} = {n \choose n-k}](https://s0.wp.com/latex.php?latex=%7Bn+%5Cchoose+k%7D+%3D+%7B%7Bn%21%7D%5Cover%7Bk%21%28n-k%29%21%7D%7D+%3D+%7B%7Bn%21%7D%5Cover%7B%28n-k%29%21%5Bn-%28n-k%29%5D%21%7D%7D+%3D+%7Bn+%5Cchoose+n-k%7D+&bg=ffffff&fg=333A42&s=0&c=20201002)













![\sum_{i=1}^n(x_i-c_1)(y_i-c_2)= \sum_{i=1}^n [(x_i-\bar{x}_n)(y_i-\bar{y}_n) ] \cdot [(\bar{x}_n - c_1)(\bar{y}_n - c_2)] =](https://s0.wp.com/latex.php?latex=%5Csum_%7Bi%3D1%7D%5En%28x_i-c_1%29%28y_i-c_2%29%3D+%5Csum_%7Bi%3D1%7D%5En+%5B%28x_i-%5Cbar%7Bx%7D_n%29%28y_i-%5Cbar%7By%7D_n%29+%5D+%5Ccdot+%5B%28%5Cbar%7Bx%7D_n+-+c_1%29%28%5Cbar%7By%7D_n+-+c_2%29%5D+%3D+&bg=ffffff&fg=333A42&s=0&c=20201002)






























